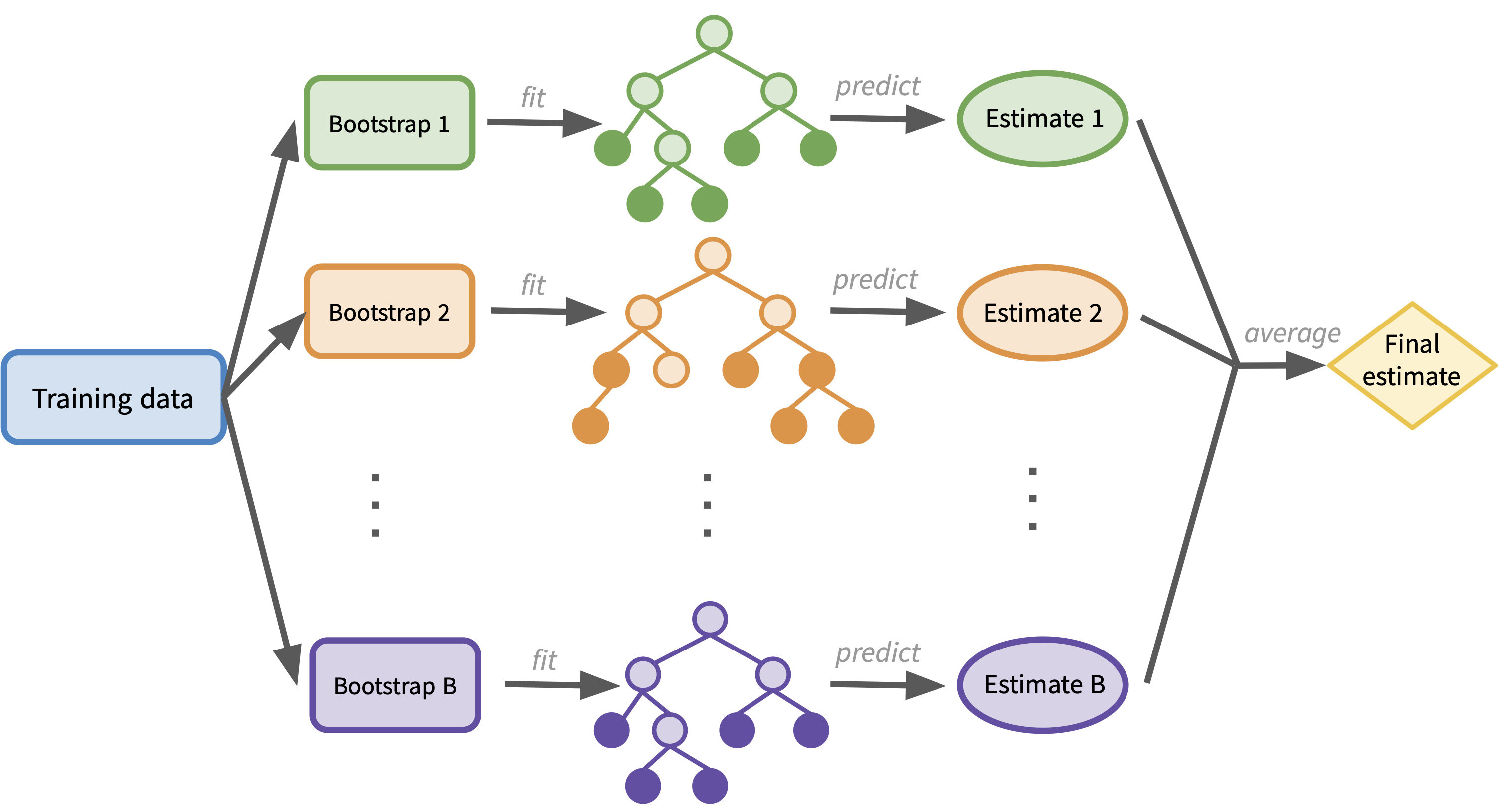
- Ensemble methods
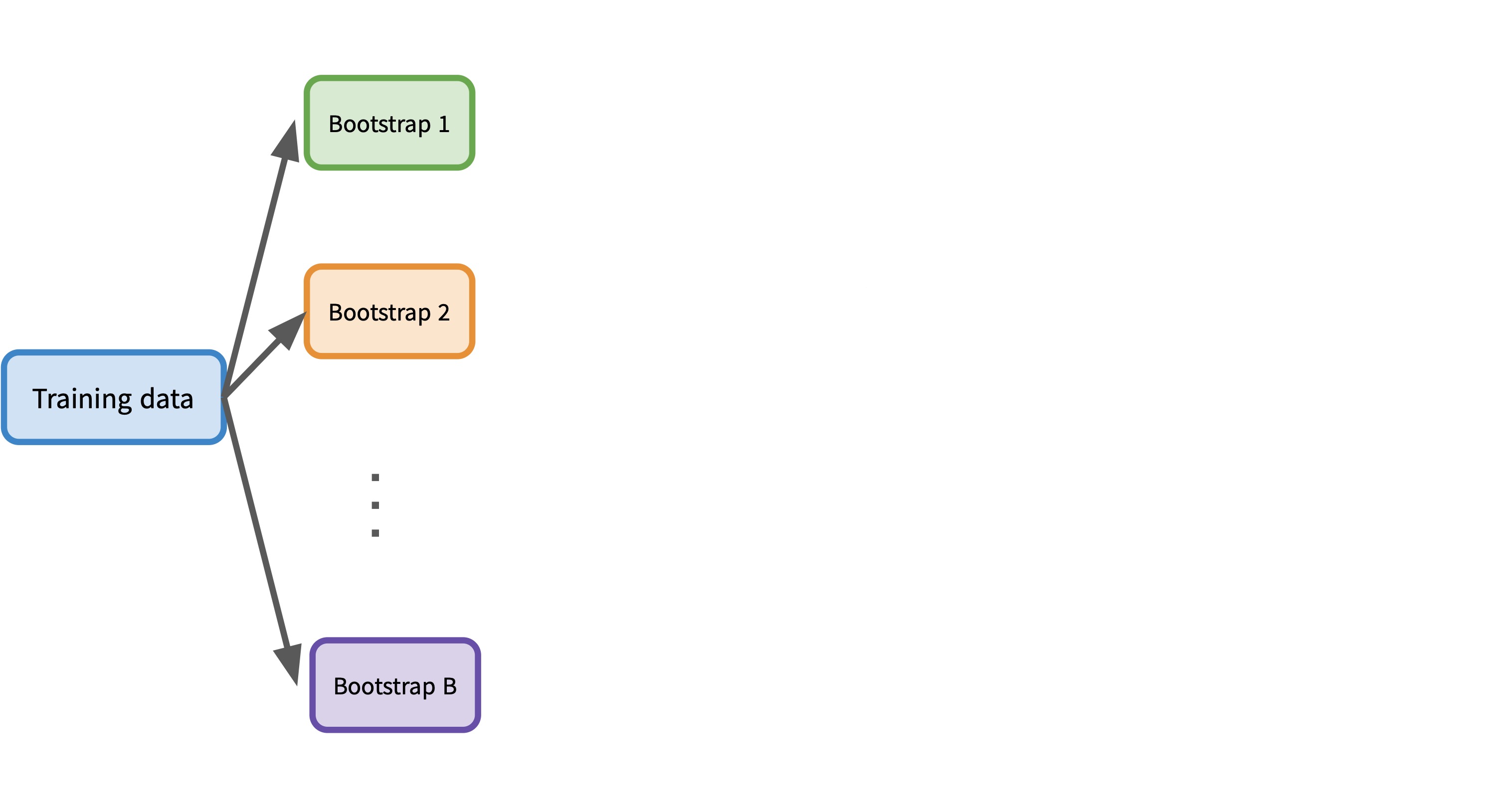
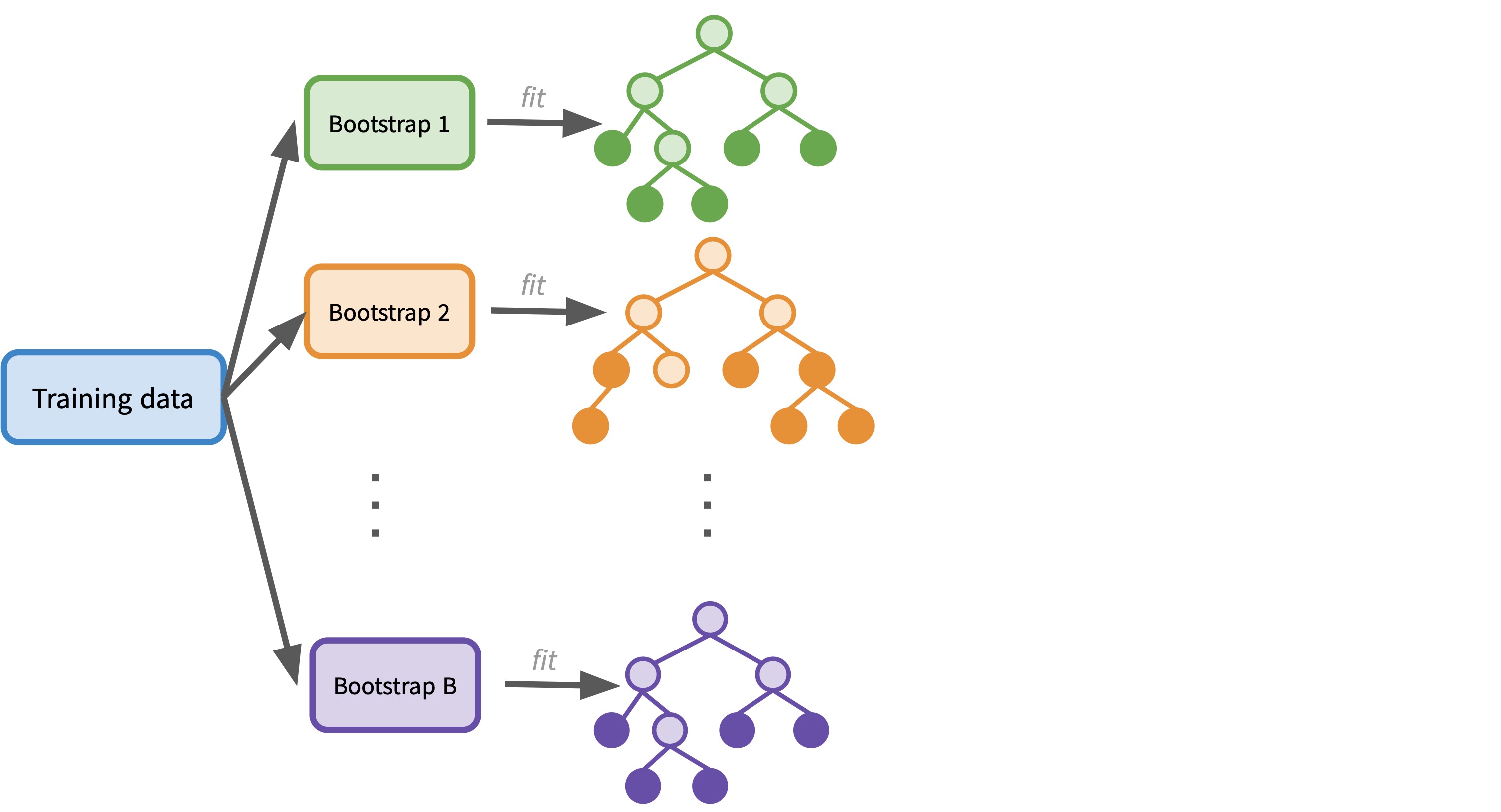
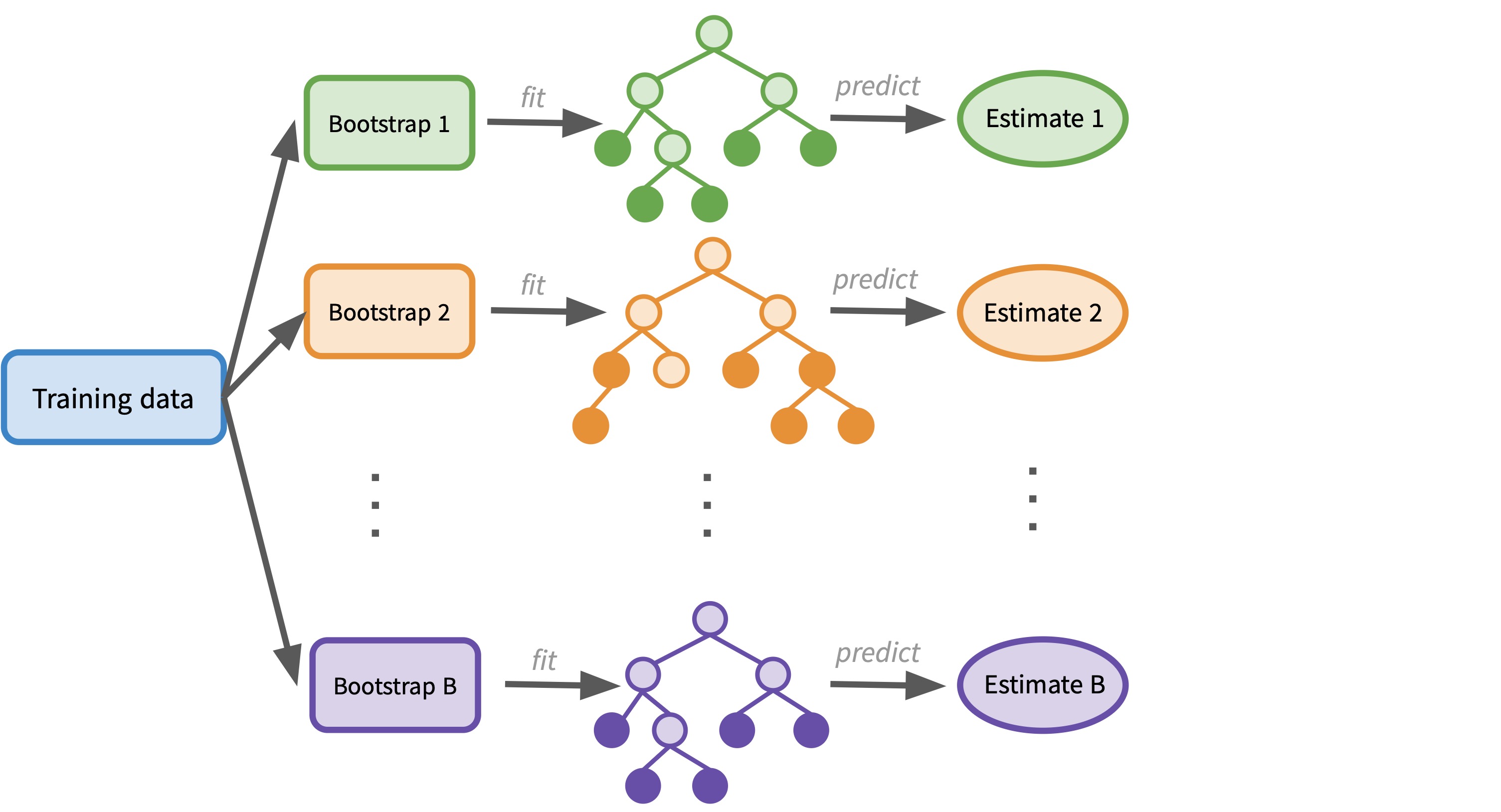
- Bagging: fitting many trees on bootstrap samples and averaging predictions
- Out-of-bag error estimation: an alternative to cross-validation
- Random forests: decorrelating trees by using a random subset of predictors at each split
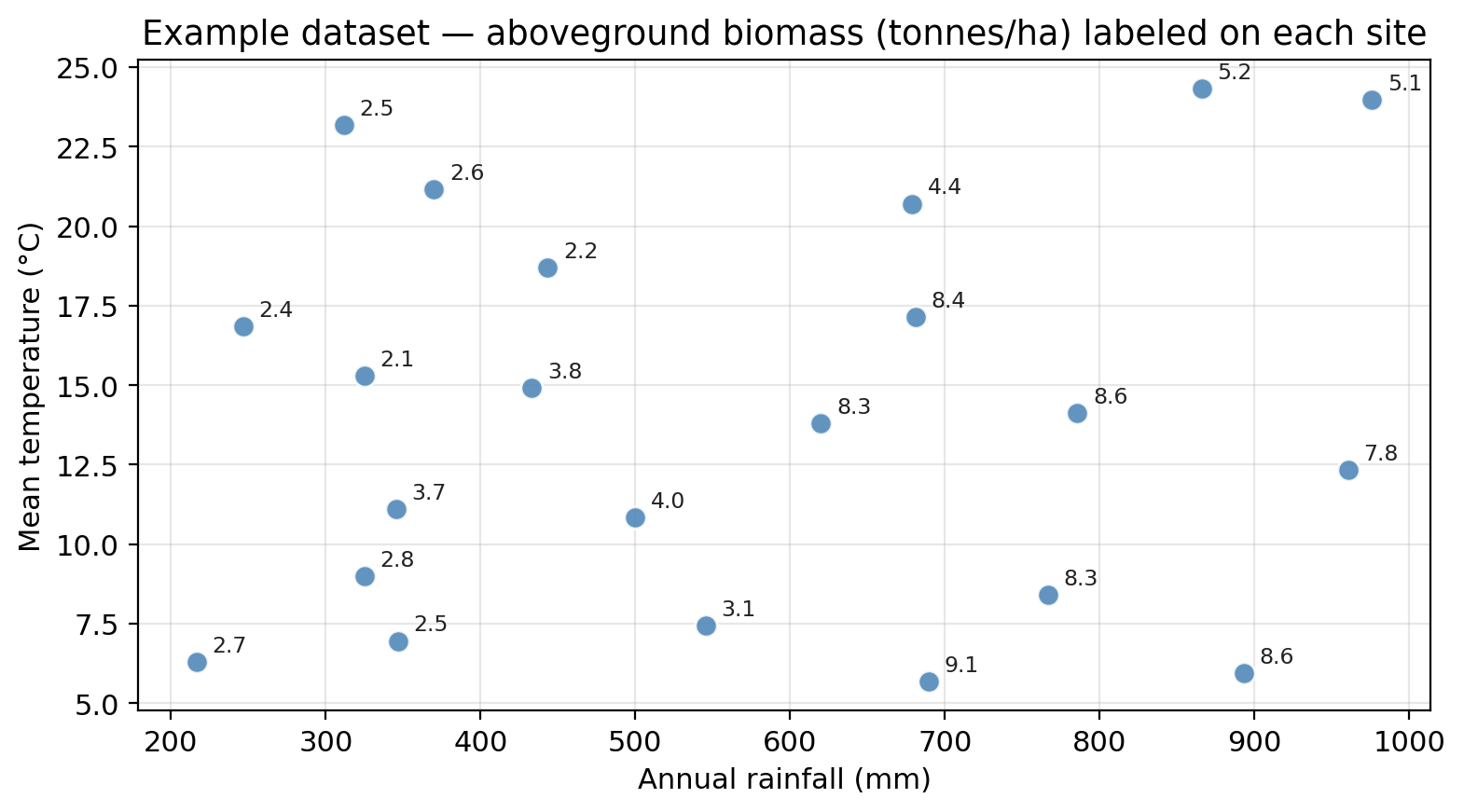
22 ecological survey sites, each characterized by:
rainfall — annual precipitation (mm)temperature — mean summer temperature (°C)biomass — aboveground plant biomass (tonnes/ha) (response)
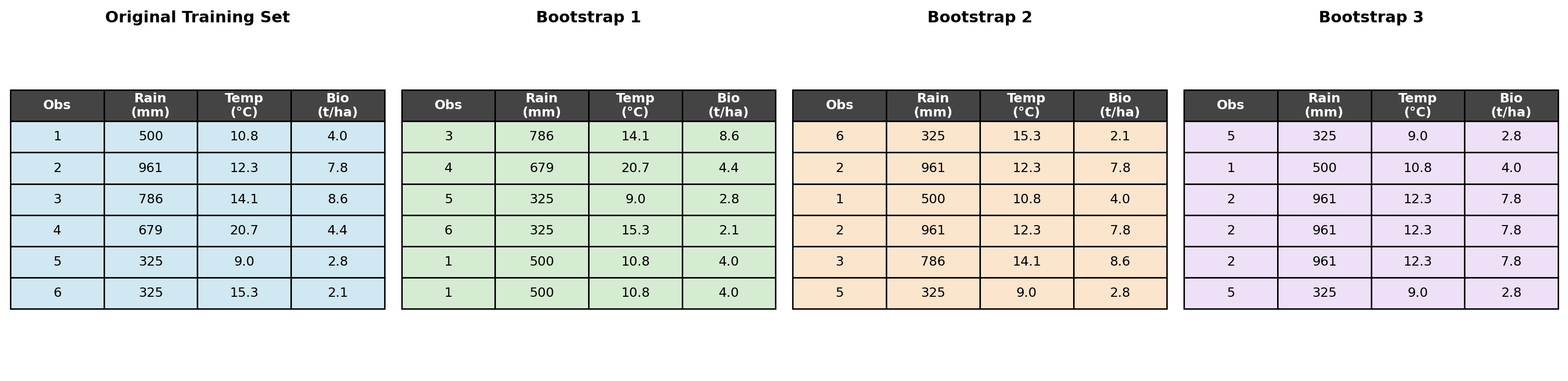
Bootstrapping: generate a new training set by sampling with replacement from the original training set
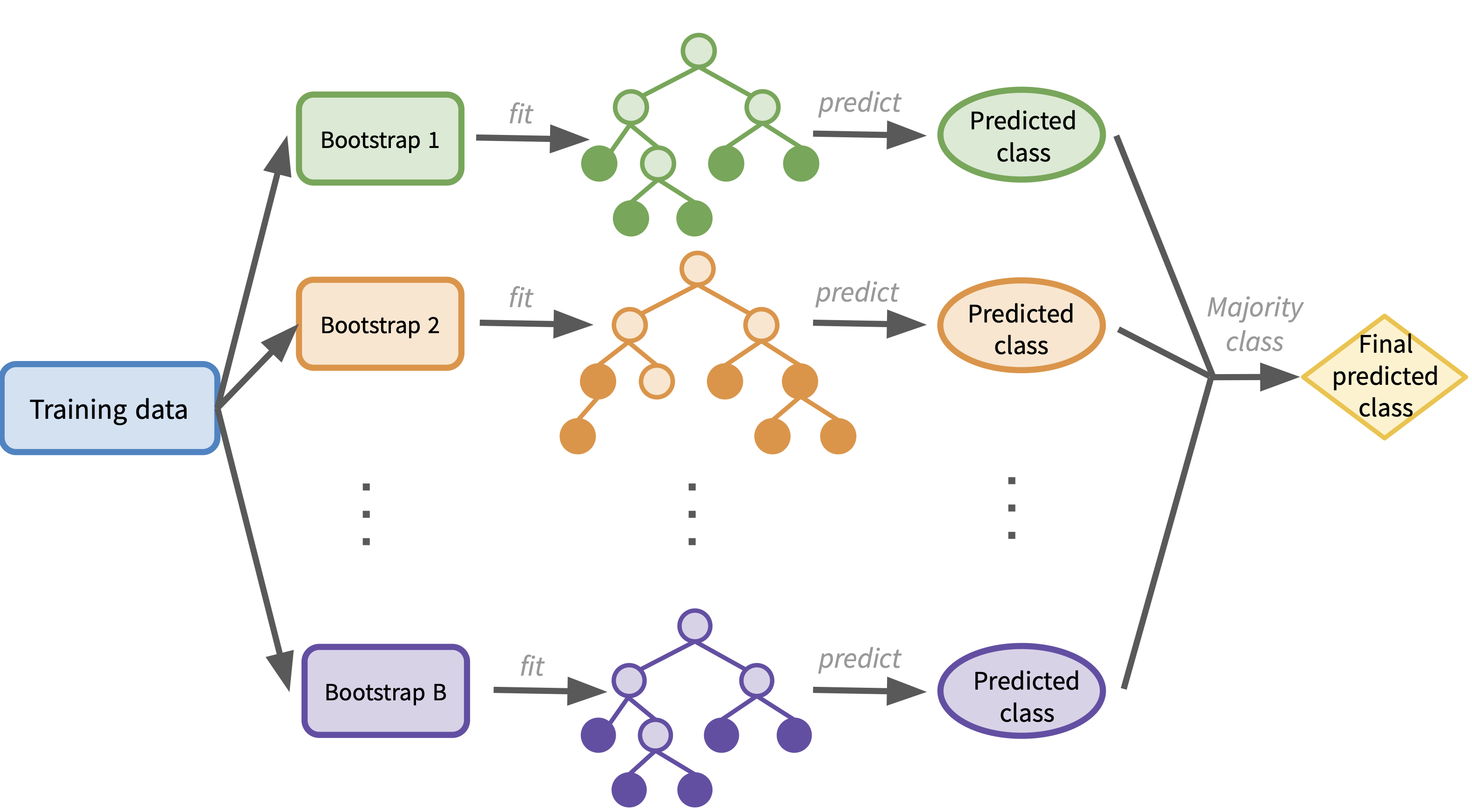
In the case of classification, the workflow is the same as the regression case, but the final aggregation step changes:
When fitting each bootstrapped tree, some of the training observations are left out of that bootstrap sample. These are called the out-of-bag (OOB) observations for that tree.
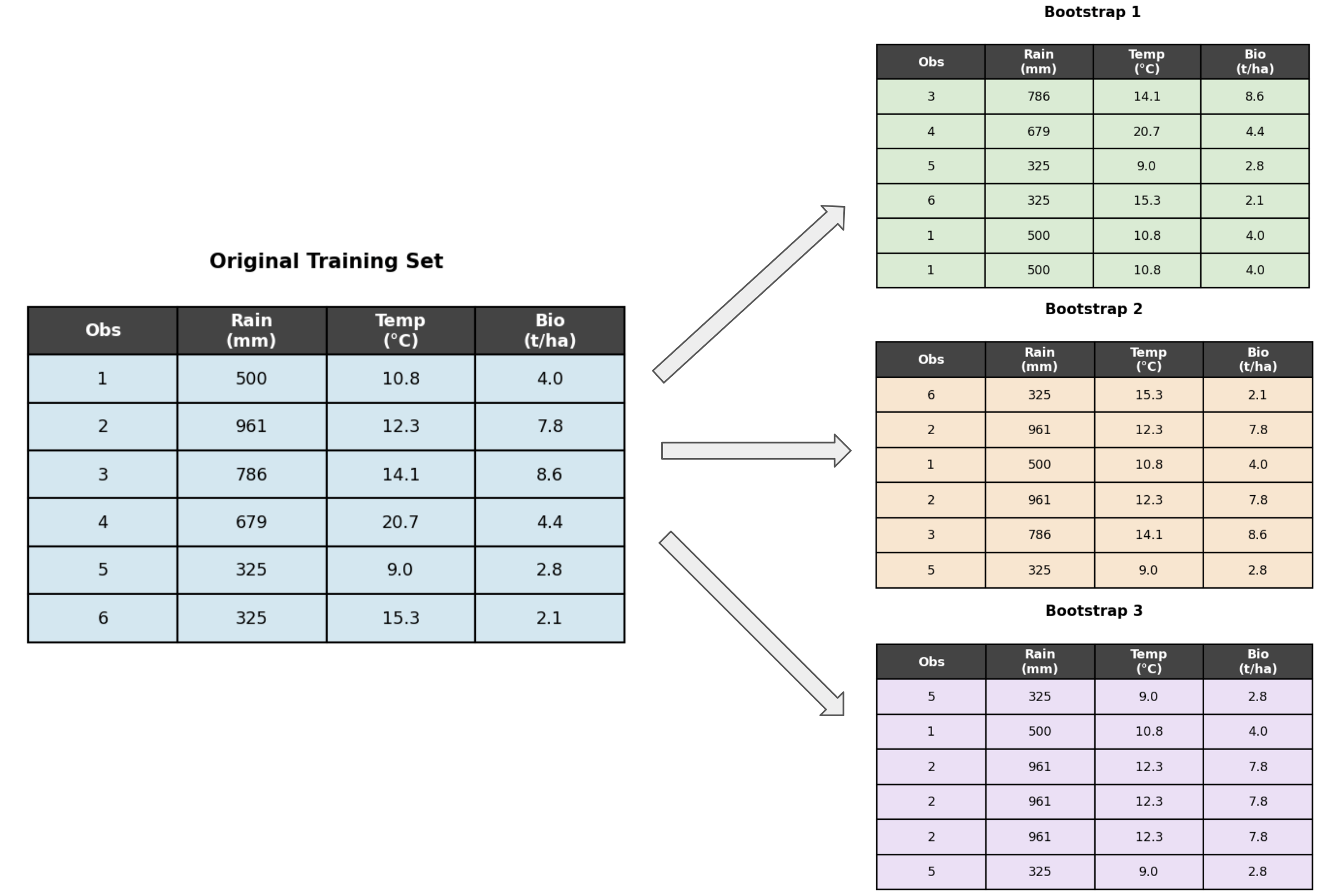
Suppose your model has three trees fit on Bootstrap samples 1, 2, and 3 shown here. For which trees would observation 4 be an OOB observation?
When fitting each bootstrapped tree, some of the training observations are left out of that bootstrap sample. These are called the out-of-bag (OOB) observations for that tree.
Suppose your model has three trees fit on Bootstrap samples 1, 2, and 3 shown here. For which trees would observation 4 be an OOB observation?
Observation 4 does not appear in Bootstrap samples 2 and 3, so it is an OOB observation for those two trees.
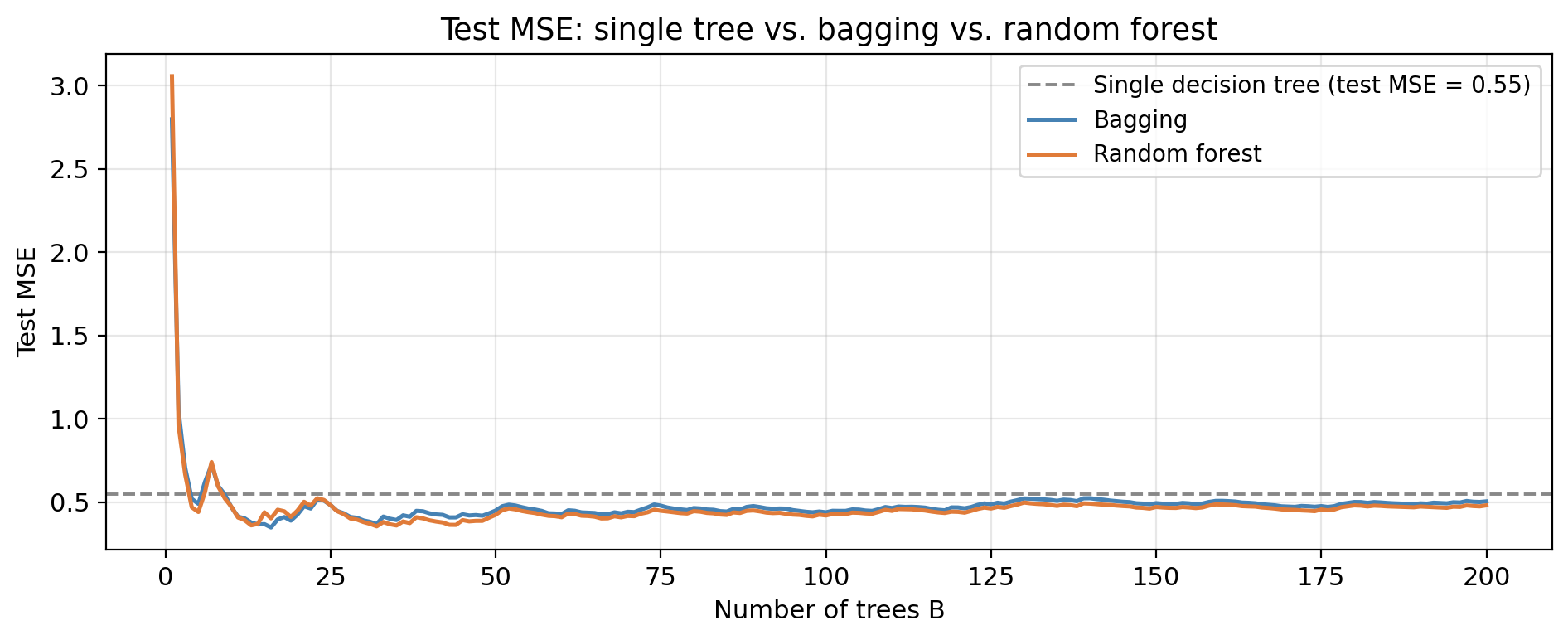
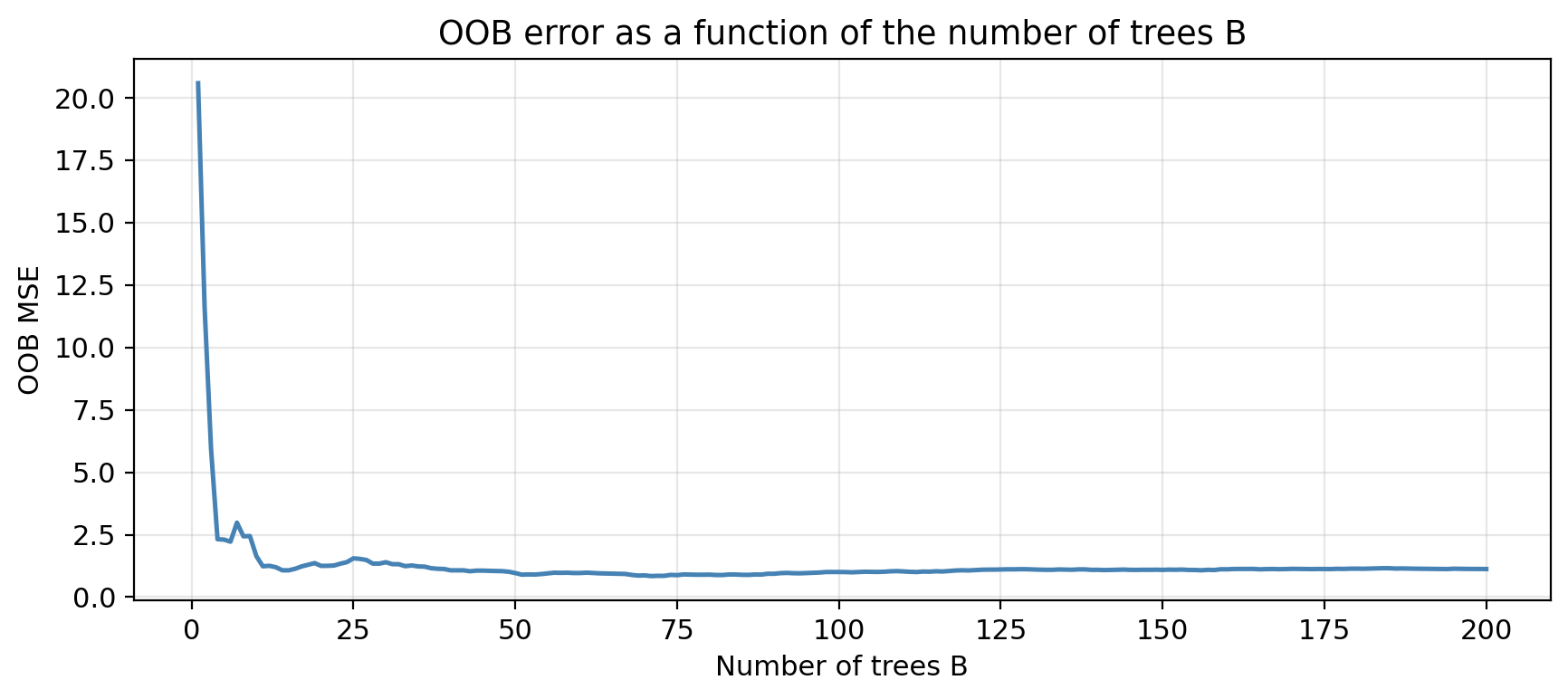
Unlike tree depth, \(B\) is not a regularization parameter. A very large \(B\) does not cause overfitting.
We pick a \(B\) large enough that the OOB error stabilizes. 100 to 500 are common defaults.
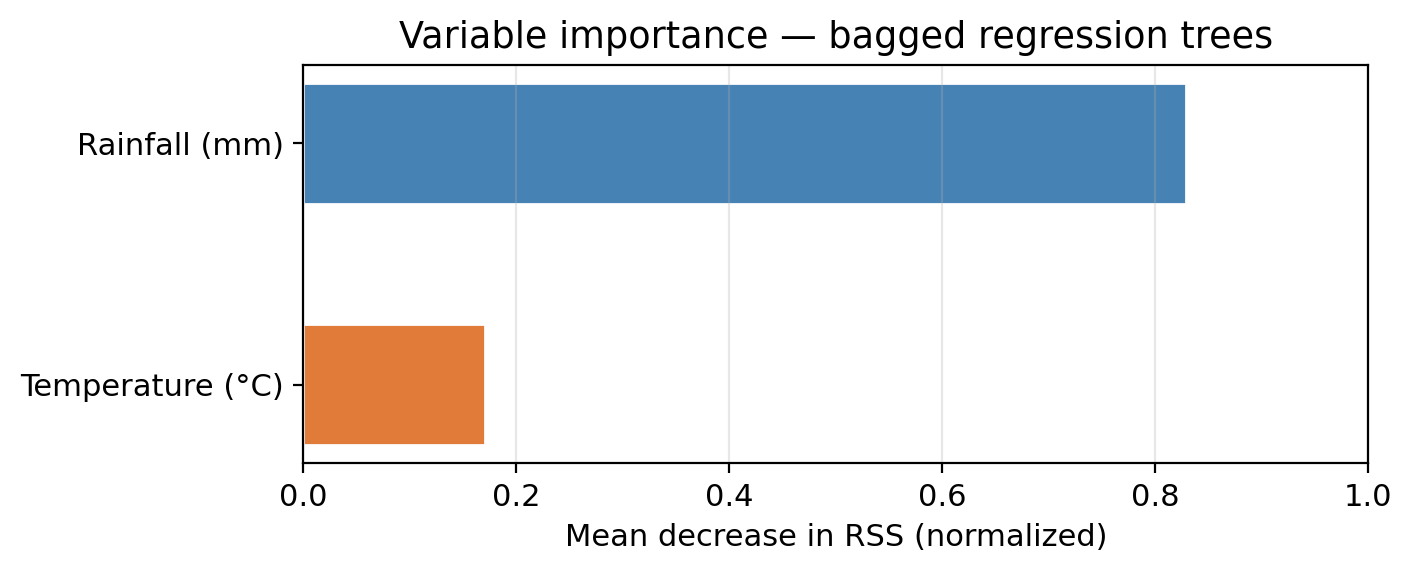
The plot shows variable importance for a model of bagged regression trees (B=200) on our example data.
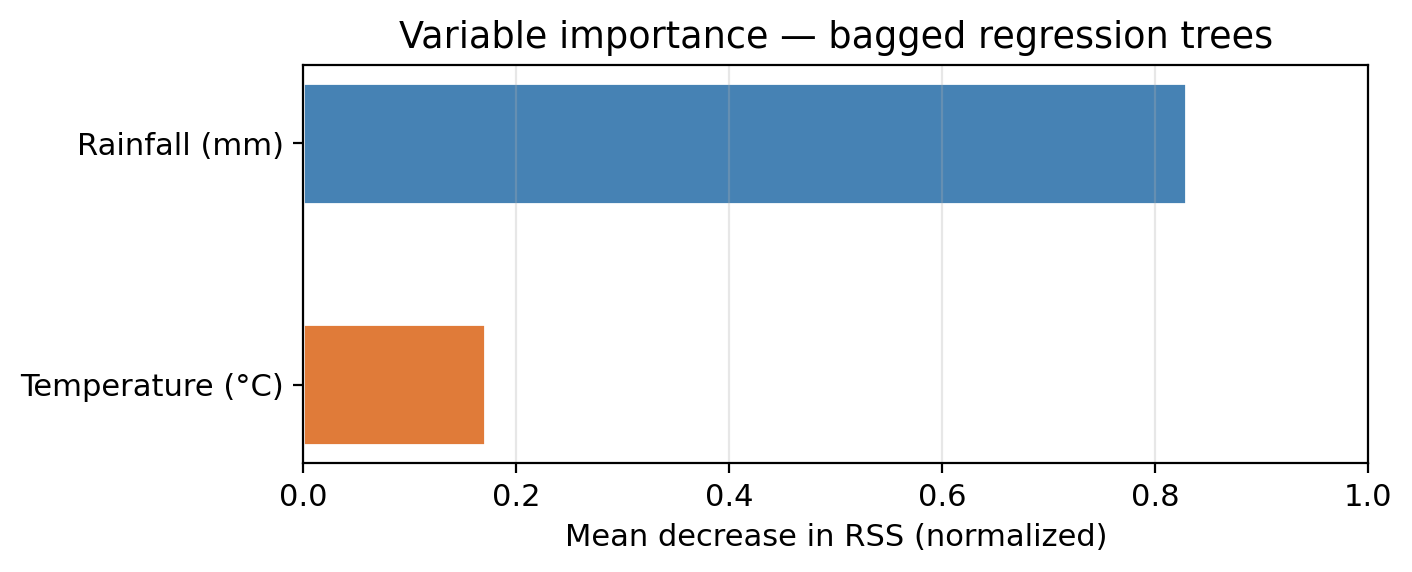
The plot shows variable importance for a model of bagged regression trees (B=200) on our example data.
Which predictor is most important for predicting biomass?
When creating the trees for the ensemble, which predictor would you expect to be used in the first split for most of them?
Rainfall: it has the largest average RSS reduction across all trees.
Rainfall: consistent with the decision tree lesson, where the root node always split on rainfall first.