What is machine learning?
In this lesson we introduce:
- What machine learning is and how it differs from traditional programming
- The relationship between AI, machine learning, and deep learning
- Examples and limitations of machine learning applied to environmental problems
What is machine learning?
You have probably heard the term machine learning a lot recently. But what does it actually mean?
Machine learning (ML) is a branch of computer science focused on building systems that can learn from data to make predictions or decisions, without being explicitly programmed with rules.
The key idea is: instead of a human writing down rules, an algorithm discovers the rules from examples.
To make this concrete, consider two approaches to the same problem: predicting whether a kelp forest has been degraded based on water temperature and sea urchin density.
Traditional programming approach:
If temperature is greater than 18°C and urchin density is greater than 50/m², then the kelp forest will be degraded
A human expert would write these rules by hand, based on their knowledge of the system.
Machine learning approach:
Give the algorithm many examples of (temperature, urchin density) and how whether these kelp forests are degraded or not. Then let the algorithm figure out the rules itself.
The rules are learned from data, not written by hand.
Think of a task in environmental science that would be very hard to solve with hand-written rules, but where you might have a lot of labeled data. What are the inputs and outputs?
At its core, a machine learning algorithm does the following:
- Take a set of training examples.
- Find a function \(\hat{f}\) that maps inputs to outputs well on those examples.
- Use \(\hat{f}\) to make predictions on new, unseen data.
“Learning” simply means adjusting \(\hat{f}\) to minimize error on the training data.
AI, machine learning, and deep learning
In addition to machine learning, you may have also heard about artificial intelligence or deep learning. These are related terms:
Artificial intelligence (AI) is the broadest term. It refers to any technique that enables machines to mimic human intelligence. This including rule-based systems, search algorithms, and more.
Machine learning is a subset of AI: systems that learn from data rather than from hand-coded rules.
Deep learning is a subset of machine learning: methods based on artificial neural networks with many layers. Deep learning is behind many recent breakthroughs, such as image recognition and large language models. It is one family of ML methods.
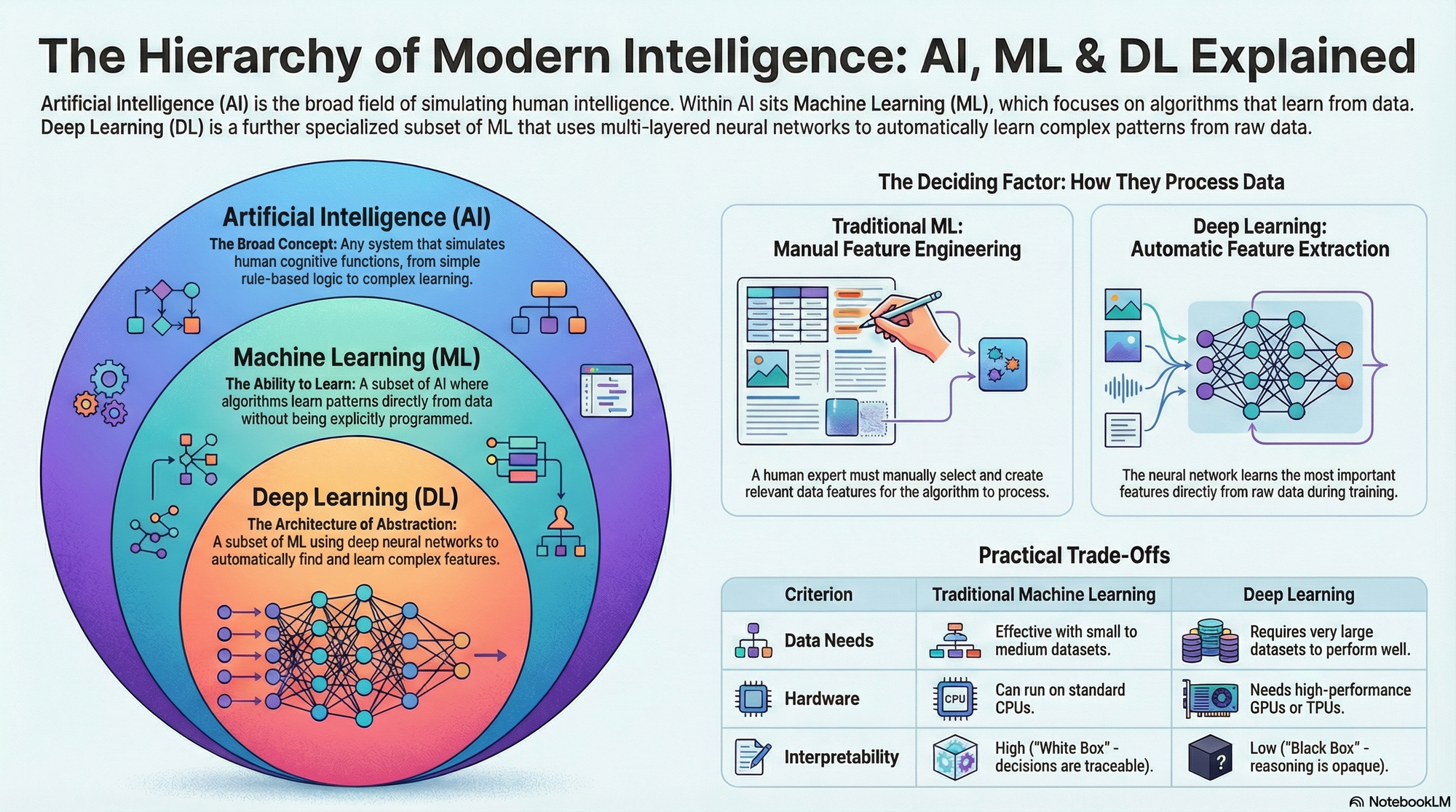
For this course, we will focus on machine learning, primarily the classical methods (regression, support vector machines, decision trees, clustering).
Machine learning in environmental science
ML is increasingly used across environmental disciplines. A few high-profile examples:
Species distribution modeling. Algorithms like MaxEnt and random forests use occurrence records and environmental covariates (temperature, precipitation, land cover) to predict where species are likely to be found
Bird detection from acoustics.Deep learning models are trained on North American and European bird species calls, enabling large-scale passive acoustic monitoring that would be impossible to do by hand.
High-resolution permafrost mapping. Deep learning methods trained on high-resolution commercial satellite imagery have been used to map and track permafrost covered in the Arctic at sub-meter scale. [C. Witharana et al., 2021]
Limitations and considerations
ML is a powerful tool, but it comes with important caveats that are especially relevant in environmental science:
Data hungry. Many ML methods need large amounts of training data, which can be scarce for rare species or remote locations.
Extrapolation risk. A model trained on data from one region or time period may perform poorly when applied elsewhere or under novel conditions.
Interpretability. Flexible models may predict well but be hard to interpret. This is a problem if you need to explain why something is changing, not just that it is.
Bias in training data. If the data used for training is unrepresentative the model will inherit those biases.
These are not reasons to avoid ML, they are reasons to use it carefully!
Construct a scenario in which developing and using a machine learning model with one or more of these limitations would be particularly consequential.