Download the lab template here and move to your eds232-labs repository.
Background
Regression problems can often contain dozens of predictors that are correlated with each other, redundant, or simply noise. Standard linear regression struggles in these settings because it spreads coefficient estimates across correlated features, inflates variance, and can overfit.
Regularization addresses this by adding a penalty to the least-squares objective that shrinks coefficient estimates toward zero, trading a small increase in bias for a potentially large reduction in variance.
To clearly observe how regularization behaves, we use a synthetic dataset with a controlled feature structure:
Feature
Role
X1, X2
Strong predictors — y is a linear function of these
X3, X4
Highly correlated with X1 and X2 (near-redundant)
X5, X6
Pure noise
In this lab we will:
Fit Ridge and Lasso regression models and compare their test performance
Understand how the regularization parameter λ controls the bias–variance trade-off
Visualize how Ridge and Lasso treat correlated and irrelevant features differently
Background: The Regularization Penalty
Both Ridge and Lasso start from the standard least squares criterion:
and add a penalty term that shrinks coefficient estimates toward zero, trading a small increase in bias for a potentially large reduction in variance.
Step 1: Load Libraries and Generate Synthetic Data
Run the cells below to import packages and generate the synthetic dataset used throughout the lab.
Code
# Import necessary librariesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import Lasso, Ridgefrom sklearn.metrics import mean_squared_error, r2_scorefrom ipywidgets import interact, FloatLogSlider# Seed for reproducibilitynp.random.seed(42)n_samples =200# True predictors (strong signal)X1 = np.random.normal(0, 1, n_samples)X2 = np.random.normal(0, 1, n_samples)# Correlated but redundant features — highly correlated with X1/X2, true coefficient = 0X3 = X1 + np.random.normal(0, 0.1, n_samples)X4 = X2 + np.random.normal(0, 0.1, n_samples)# Pure noise features — same scale as true features so they genuinely competeX5 = np.random.normal(0, 1, n_samples)X6 = np.random.normal(0, 1, n_samples)X = np.column_stack([X1, X2, X3, X4, X5, X6])y =3* X1 +2* X2 + np.random.normal(0, 0.5, n_samples)
Code
# Split data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Note: Our synthetic data were drawn from N(0,1), so they are already on the same scale. However, with real environmental data that is often not on the same scale, you would need to scale at this point.
Step 2: Fit Ridge Regression
Ridge regression estimates coefficients by minimizing:
\[\text{RSS} + \lambda \sum_{j=1}^{p} \beta_j^2\]
The term \(\lambda \sum \beta_j^2\) is the shrinkage penalty. It grows when coefficients are large, so the optimizer is pushed toward smaller values. The tuning parameter \(\lambda \geq 0\) controls the bias–variance trade-off:
When \(\lambda = 0\), Ridge reduces to ordinary least squares
As \(\lambda \to \infty\), all coefficients shrink toward (but never reach) zero
Ridge keeps all predictors in the model. It shrinks their coefficients but never sets any exactly to zero.
Fit a Ridge model using sklearn’s default λ and evaluate its performance on the test set.
Code
# Create and fit Ridge regression modelridge_model = Ridge()ridge_model.fit(X_train, y_train)ridge_predictions = ridge_model.predict(X_test)# Calculate MSE and R^2 for Ridge regressionridge_mse = mean_squared_error(y_test, ridge_predictions)ridge_r2 = r2_score(y_test, ridge_predictions)print("Ridge Regression MSE:", ridge_mse)print("Ridge Regression R²:", ridge_r2)
The Lasso swaps the \(\ell_2\) penalty for an \(\ell_1\) penalty:
\[\text{RSS} + \lambda \sum_{j=1}^{p} |\beta_j|\]
This small change has a major consequence: the \(\ell_1\) penalty can force coefficient estimates to be exactly zero, removing predictors from the model completely. This is what makes Lasso models much easier to interpret than Ridge.
Fit a Lasso model using sklearn’s default λ and compare its performance to Ridge.
Code
# Create and fit Lasso regression modellasso_model = Lasso()lasso_model.fit(X_train, y_train)lasso_predictions = lasso_model.predict(X_test)# Calculate MSE and R^2 for Lasso regressionlasso_mse = mean_squared_error(y_test, lasso_predictions)lasso_r2 = r2_score(y_test, lasso_predictions)print("Lasso Regression MSE:", lasso_mse)print("Lasso Regression R²:", lasso_r2)
What do you notice? Compare the Lasso MSE to Ridge. Why might Lasso perform worse at the default λ? What does this suggest about the default regularization strength?
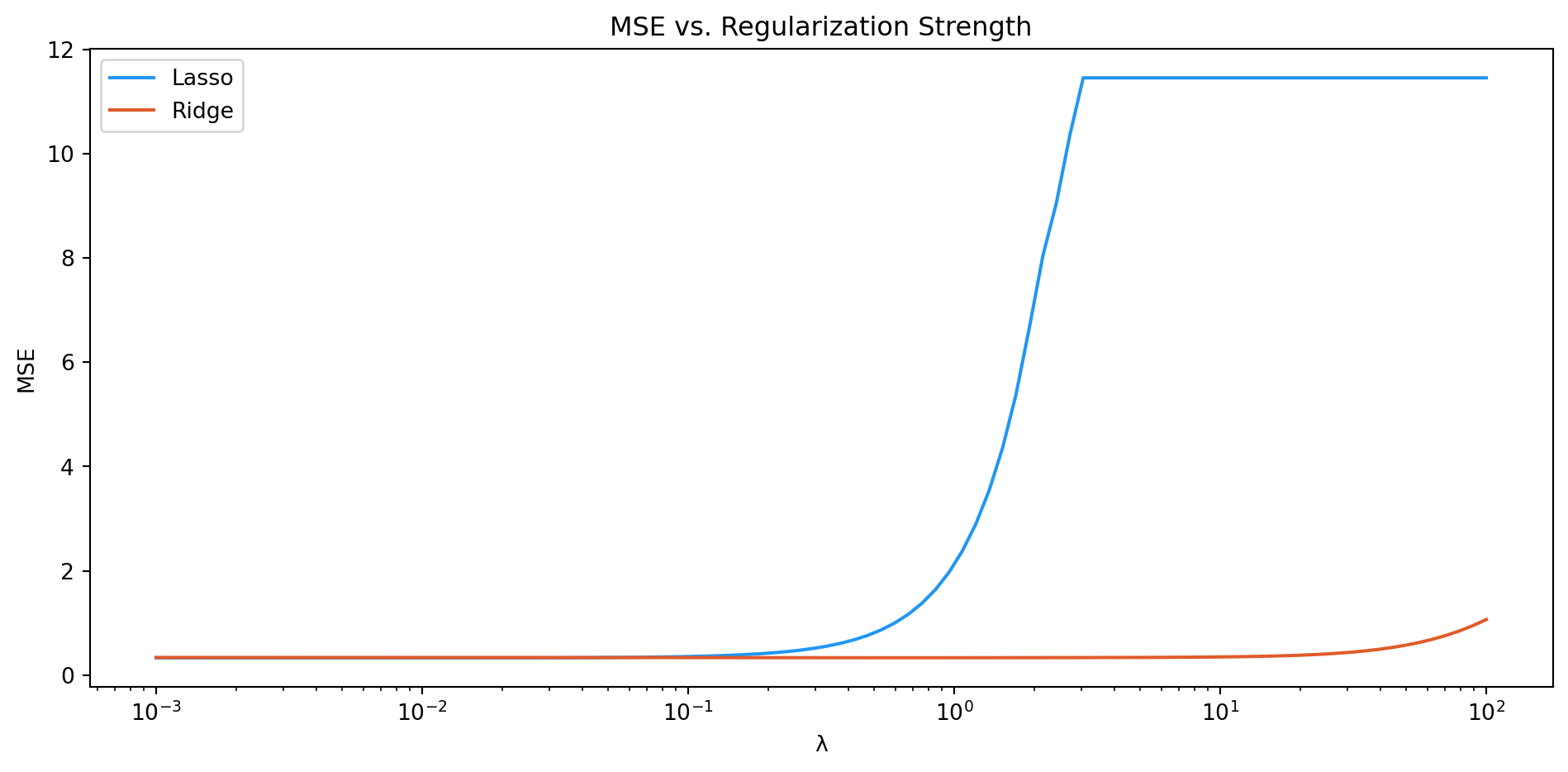
Step 4: Tune λ and compare MSE Across Regularization Strengths
Create a visualization of λ values ranging from 0.001 to 100 and the MSE that these values yield. Create a line for both ridge and lasso.
Code
# Visualize lambdas against MSE for Lasso and Ridgemse_lasso = []mse_ridge = []lambdas = np.logspace(-3, 2, 100) # 100 values from 0.001 to 100for lam in lambdas: lasso = Lasso(alpha=lam) ridge = Ridge(alpha=lam) lasso.fit(X_train, y_train) ridge.fit(X_train, y_train) mse_lasso.append(mean_squared_error(y_test, lasso.predict(X_test))) mse_ridge.append(mean_squared_error(y_test, ridge.predict(X_test)))plt.figure(figsize=(10, 5))plt.plot(lambdas, mse_lasso, label='Lasso', color='#2196F3')plt.plot(lambdas, mse_ridge, label='Ridge', color='#E05B2B')plt.xscale('log')plt.xlabel('λ')plt.ylabel('MSE')plt.title('MSE vs. Regularization Strength')plt.legend()plt.tight_layout()plt.show()
What do you notice? At what λ does each model reach its minimum test MSE? Which model is more sensitive to the choice of λ? What happens to both models as λ becomes very large?
Step 5: Explore Predictions Interactively
Create an interactive plot that shows how our predictions change as our penalty parameter changes.
Try this: Set λ to a very large value (e.g., 10 or 100) for both models. What happens to the predictions? Now set λ very small (e.g., 0.001). Why do you think a \(\lambda\) of 0 fits the best with this data?
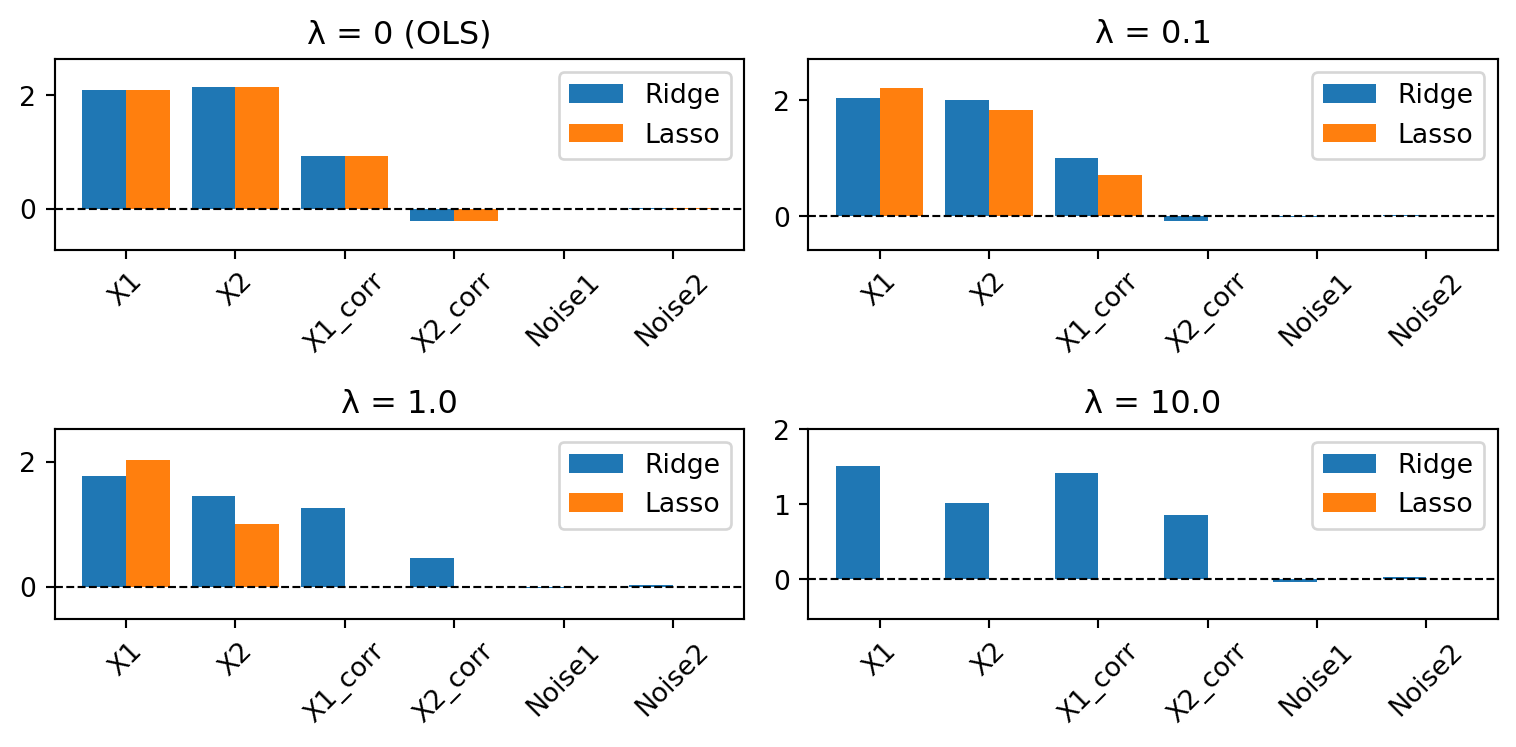
Step 6: Compare Coefficient Behavior Across λ Values
Create plots to show how Ridge and Lasso coefficients change at four different values of λ (including λ = 0 (OLS)). Take note of how Lasso zeros out correlated and noise features (variable selection), while Ridge only shrinks them toward zero without ever eliminating them.
What do you notice? Compare the Ridge and Lasso bars at each λ level. Which features does Lasso zero out first? How does Ridge handle the correlated features X3 and X4 compared to Lasso? What are the trade-offs between the two approaches for model interpretability?